APP启动之前,它在想些什么?
[TOC]
前言
关于各种编程语言的理解,请见我另一篇文章《理解编程的各种语言》。
程序启动之前的准备活动,总的来说是:
- 编译
- 预编译
- 词法分析
- 语法分析
- 语义分析
- 中间代码生成
- 代码优化
- 目标代码生成
- 汇编
- 链接
- 装入
- 动态链接
编码阶段——从人所能理解的语言到机器所能理解的语言
在这里推荐一篇博文:美团点评技术团队的博文:高级语言的编译:链接及装载过程介绍
编译
一般就是把源文件转化成一个一个的二进制目标文件。但这一步会留下一些坑,就是一些使用的其他文件的里的函数和变量会暂时不明确具体访问地址,留给下一步解决。
编译主要依靠编译器来完成一系列的操作,主要的操作有预处理、词法分析、语法分析、语义分析、生成中间代码、生成目标代码以及目标代码优化。
编译程序的工作过程如下图所示:

OC的编译链接执行过程图如下:


OS X 现在使用的编译器是 LLVM (Low Level Virtual Machine),最初使用GCC作为官方的编译器。iOS编译采用Clang作为编译器前端,LLVM作为编译器后端。更多关于GCC、LLVM、Clang的关系及区别后面会详细说明。
预编译
预处理主要是处理一些宏定义,比如#define、#include、#if 等。预处理的实现有很多种,有的编译器会在词法分析前先进行预处理,替换掉所有开头的宏,而有的编译器则是在词法分析的过程中进行预处理。当分析到开头的单词时才进行替换。虽然先预处理再词法分析比较符合直觉,但在实际使用中,GCC 使用的却是一边词法分析,一边预处理的方案。主要工作为:
- 删除所有#define, 展开所有宏定义
- 理所有预编译指令, 如#if, #ifdef, #elif, #else, #endif
- 递归处理#include
- 删除所有注释, // 和 /**/
- 添加行号和文件名标识
- 保留所有#pragma编译器指令
词法分析
将输入分解为一个个独立的词法符号,也叫单词符号(token)
// find a zero
float matchZero(char *s) {
} 上面的小程序,返回下列单词流
FLOAT、ID(MATCHZERO)、LPAREN、CHAR、ID(S) 、RPAREN //注释、宏、空格、换行等都不是单词
在词法分析阶段,源程序可以简单的看做是一个多行的字符串。词法分析阶段是编译过程的第一阶段,主要任务是对源程序从前到后(从左到右)逐个字符进行扫描,从中识别出一个个“单词”符号。词法分析程序输出的”单词“常采用二元组的方式,即单词类别和单词自身的值。词法分析过程依据的语言的此法规则,即描述“单词”结构的规则。
词法分析的主要难点在于,前缀无法决定一个完整字符串的含义,通常需要看完整句以后才知道每个单词的具体含义。同时,C 语言的语法也不简单,各种关键字,括号,逗号,语法等等都会给词法分析的实现增加难度。
词法分析的主要实现原理是状态机,它逐个读取字符,然后根据读到的字符的特点转换状态。比如这是 GCC 的词法分析状态机(引用自《编译系统透视》):
语法分析
经过词法分析以后,编译器已经知道了每个单词,但这些单词组合起来表示的语法还不清楚。语法分析只考虑构成该句子的语法单位是否符合语法规则。例如在分析除法表达式时在语法分析阶段只分析运算符左右两边是否为变量、常量、表达式等,而不去管除数是否为0。
一个简单的思路是模板匹配,比如有这样的语句:
int a = 10;
它其实表示了这么一种通用的语法格式:
类型 变量名 = 常量;
所以上面的语句当然可以匹配这种模式。同理它不可能匹配类型 函数名(参数)这样的函数定义模式,因为两者结构不一致,等号无法被匹配。
语法分析比词法分析更复杂,因为所有 C 语言支持的语法特性都必须被语法分析器正确的匹配,这个难度比纯新手学习 C 语言语法难上很多倍。不过这个属于业务复杂性,无论采用哪种解决方案都不可避免,因为语法规则的数量就是这么多。
在匹配模式的时候,另一个问题在于上述的名词,比如 类型、参数,很难界定。比如int 是类型,long long 也是类型,unsigned long long 也是类型。(int a) 可以是参数,(int a, int b) 也是参数,(unsigned long long a, long long double b, int *p) 看起来能把人逼疯。
下面举一个简单的例子来解释 int a = 10 是如何被解析的,总的思路是归纳与分解。我们把一个复杂的式子分割成若干部分,然后分析各个部分,这样可以简化复杂度。对于 int a = 10 来说,他是一个声明,声明由两部分组成,分别是声明说明符和初始声明符列表:
| 声明 | 声明说明符 | 初始声明符列表 |
|---|---|---|
| int a = 10 | int | a = 10 |
| int fun(int a) | int | fun(int a) |
| int array[5] | int | array[5] |
声明说明符比较简单,它其实是若干个类型的串联:
声明说明符 = 类型 + 类型的数组(长度可以为 0)
而且我们知道若干个类型连在一起又变成了声明说明符,所以上述等式等价于:
声明说明符 = 类型 + 声明说明符(可选)
再严谨一些,声明说明符还可以包括 const 这样的限定说明符,inline 这样的函数说明符,和 _Alignas 这样的对齐说明符。借用书中的公式,它的完整表达如下:
这才仅仅是声明语句中最简单的声明说明符,仅仅是几个类型和关键字的组合而已。后面的初始声明符列表的解析更复杂。如果有能力做完这些解析,恭喜你,成功的解析了声明语句。你会发现什么定义语句啦,调用语句啦,正妩媚的向你招手╮(╯▽╰)╭。
成功解析语法以后,我们会得到抽象语法树(AST: Abstract Syntax Tree)。以这段代码为例:
int fun(int a, int b) {
int c = 0;
c = a + b;
return c;
}
它的语法树如下:
语法树将字符串格式的源代码转化为树状的数据结构,更容易被计算机理解和处理。但它距离中间代码还有一定的距离。
语义分析
语义分析阶段主要是检查源程序是否存在语义错误,并收集类型信息供后面的代码生成阶段使用,只有语法和语义都正确的源程序才能翻译成正确的目标代码。语义分析主要做的事情就是类型检查、以及符号表管理。
语法分析只能完成语法层面的分析,无法对整个语句的真正意义进行判别。进行类型审查时,会审查每个运算符是否具有语言规范允许的运算对象,当不符合语言规范时,编译程序应报告错误。比如:
将一个浮点数赋值指针类型的时候,语义分析器就会发现类型不匹配,编译器提出相应的错误警告;有的编译程序要对实数用作数组下标的情况报告错误;再如分析除法表达式时,在语义分析阶段就要分析该表达式的除数是否为零等。
中间代码生成
中间代码是一种简单且含义明确的记号系统,可以有若干种形式,常见的有逆波兰记号、四元式、三元式和树。他们的共同特征是代码的方式与具体的机器无关。中间语言的复杂性介于源程序语言和机器语言之间。
编译器前端(如Clang)负责产生机器无关的中间代码,编译器后端(如LLVM)负责对中间代码进行优化并转化为目标机器代码。中间代码实际上起一个编译器前段与后端分水岭的作用,目的是便于编译器的开发和移植和代码的优化。
生成中间代码是非常重要的一步,一方面它和语言无关,也和 CPU 与具体实现无关。可以理解为中间代码是一种非常抽象,又非常普适的代码。它客观中立的描述了代码要做的事情,如果用中文、英文来分别表示 C 和 Java 的话,中间码某种意义上可以被理解为世界语。
另一方面,中间代码是编译器前端和后端的分界线。编译器前端负责把源码转换成中间代码,编译器后端负责把中间代码转换成汇编代码。
下图对于中间代码的作用一目了然:

其实中间代码可以被省略,抽象语法树可以直接转化为目标代码(汇编代码)。然而,不同的 CPU 的汇编语法并不一致,比如 AT&T与Intel汇编风格比较 这篇文章所提到的,Intel架构和 AT&T 架构的汇编码中,源操作数和目标操作数位置恰好相反。Intel 架构下操作数和立即数没有前缀但 AT&T 有。因此一种比较高效的做法是先生成语言无关,CPU 也无关的中间代码,然后再生成对应各个 CPU 的汇编代码。
以gcc为例,生成中间代码可以分为三个步骤:
1.语法树转高端gimple:这一步主要是处理寄存器和栈,比如 c = a + b 并没有直接的汇编代码和它对应,一般来说需要把 a + b 的结果保存到寄存器中,然后再把寄存器赋值给 c。所以这一步如果用 C 语言来表示其实是:
int temp = a + b; // temp 其实是寄存器
c = temp;
另外,调用一个新的函数时会进入到函数自己的栈,建栈的操作也需要在 gimple 中声明。
2.高端 gimple 转低端 gimple:这一步主要是把变量定义,语句执行和返回语句区分存储。比如:
int a = 1;
a++;
int b = 1;
会被处理成:
int a = 1;
int b = 1;
a++;
这样做的好处是很容易计算一个函数到底需要多少栈空间。
此外,return 语句会被统一处理,放在函数的末尾,比如:
if (1 > 0) {
return 1;
}
else {
return 0;
}
会被处理成:
if (1 > 0) {
goto a;
}
else {
goto b;
}
a:
return 1;
b:
return 0;
3.低端 gimple 经过 cfa 转 ssa 再转中间代码:这一步主要是进行各种优化,添加版本号等,我不太了解,对于普通开发者来说也没有学习的必要。
LLVM IR 是一种中间代码,它长成这样:
define i32 @square_unsigned(i32 %a) {
%1 = mul i32 %a, %a
ret i32 %1
}
代码优化
编译器后端主要包括代码生成器、代码优化器。代码生成器将中间代码转换为目标代码,代码优化器主要是进行一些优化,比如删除多余指令,选择合适寻址方式等。
代码优化是指对程序进行多种等价变换,使得从变换后的程序出发,能生成更有效的目标代码。所谓等价,是指不改变程序的运行结果。所谓有效,主要指目标代码运行时间较短,以及占用的存储空间较小。这种变换称为优化。
两类优化:一类是对语法分析后的中间代码进行优化,它不依赖于具体的计算机;另一类是在生成目标代码时进行的,它在很大程度上依赖于具体的计算机。对于前一类优化,根据它所涉及的程序范围可分为局部优化、循环优化和全局优化三个不同的级别。
#####目标代码生成 目标代码生成是编译的最后一个阶段。目标代码生成器把语法分析后或优化后的中间代码变换成目标代码(.obj)。目标代码生成阶段的工作与目标机器的体系结构密切相关。
三种形式:
① 可以立即执行的机器语言代码,所有地址都重定位;
② 待装配的机器语言模块,当需要执行时,由连接装入程序把它们和某些运行程序连接起来,转换成能执行的机器语言代码;
③ 汇编语言代码,须经过汇编程序汇编后,成为可执行的机器语言代码。
目标代码生成阶段应考虑直接影响到目标代码速度的三个问题:
一是如何生成较短的目标代码;
二是如何充分利用计算机中的寄存器,减少目标代码访问存储单元的次数;
三是如何充分利用计算机指令系统的特点,以提高目标代码的质量。
目标文件的样子(以linux下的elf文件格式为例)

夹在ELF头和节头部表之间的都是节。一个典型的ELF可重定位目标文件包含下面几个节:
- .text:已编译程序的机器代码。
- .rodata:只读数据,比如printf语句中的格式串和开关(switch)语句的跳转表。
- .data:已初始化的全局C变量。局部C变量在运行时被保存在栈中,既不出现在.data中,也不出现在.bss节中。
- .bss:未初始化的全局C变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分初始化和未初始化变量是为了空间效率在:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。
- .symtab:一个符号表(symbol table),它存放在程序中被定义和引用的函数和全局变量(包括引用到的外部变量和函数,不含有局部变量)的信息。一些程序员错误地认为必须通过-g选项来编译一个程序,得到符号表信息。实际上,每个可重定位目标文件在.symtab中都有一张符号表。然而,和编译器中的符号表不同,.symtab符号表不包含局部变量的表目。
- .rel.text:当链接噐把这个目标文件和其他文件结合时,.text节中的许多位置都需要修改。一般而言,任何调用外部函数或者引用全局变量(包括本目标文件内的全局变量,因为在链接时要多个目标文件的相同段合并,这样数据的地址就会改变,所以要重定位)的指令都需要修改。另一方面调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非使用者显式地指示链接器包含这些信息。
- .rel.data:被模块定义或引用的任何全局变量的信息。一般而言,任何已初始化全局变量的初始值是全局变量或者外部定义函数的地址都需要被修改。
- .debug:一个调试符号表,其有些表目是程序中定义的局部变量和类型定义,有些表目是程序中定义和引用的全局变量,有些是原始的C源文件。只有以-g选项调用编译驱动程序时,才会得到这张表。
- .line:原始C源程序中的行号和.text节中机器指令之间的映射。只有以-g选项调用编译驱动程序时,才会得到这张表。
- .strtab:一个字符串表,其内容包括.symtab和.debug节中的符号表,以及节头部中的节名字。字符串表就是以null结尾的字符串序列。
旁注:为什么未初始化的数据称为.bss?
用术语.bss来表示未初始化的数据是很普遍的。它起始于IBM 704汇编语言(大约在1957年)中”块存储开始(Block Storage Start)“指令的首字母缩写,并沿用至今。一个记住区分.data和.bss节的简单方法是把“bss”看成是“更好地节省空间(Better Save Space)!“的缩写。
汇编
汇编器会接收汇编代码,将它转换成二进制的机器码,生成目标文件(后缀是 .o),机器码可以直接被 CPU 识别并执行。从目标代码可以猜出来,最终的目标文件(机器码)也是分段的,这主要有以下三个原因:
- 分段可以将数据和代码区分开。其中代码只读,数据可写,方便权限管理,避免指令被改写,提高安全性。
- 现代 CPU 一般有自己的数据缓存和指令缓存,区分存储有助于提高缓存命中率。
- 当多个进程同时运行时,他们的指令可以被共享,这样能节省内存。
链接
链接就是将不同部分的代码和数据收集和组合成一个单一文件的过程,也就是把不同目标文件合并成最终可执行文件的过程。当然,务必知道:这个过程不涉及内存。链接可以分为三种情形:1,编译时链接,也就是我们常说的静态链接;2,装载时链接;3,运行时链接。装载时链接和运行时链接合称为动态链接。在此,我们的链接部分将主要讲述静态链接,而装载时链接我们放在装载部分讲,运行时链接忽略。
静态链接
静态链接就是将多个目标文件组合在一起形成一个可执行文件,如将a.o 和 b.o 链接在一起形成 可执行文件ab.out。
在一个目标文件中,不可能所有变量和函数都定义在文件内部。比如 strlen 函数就是一个被调用的外部函数,此时就需要把 main.o 这个目标文件和包含了 strlen函数实现的目标文件链接起来。我们知道函数调用对应到汇编其实是 jump 指令,后面写上被调用函数的地址,但在生成 main.o 的过程中,strlen() 函数的地址并不知道,所以只能先用 0 来代替,直到最后链接时,才会修改成真实的地址。
链接器就是靠着重定位表来知道哪些地方需要被重定位的。每个可能存在重定位的段都会有对应的重定位表。在链接阶段,链接器会根据重定位表中,需要重定位的内容,去别的目标文件中找到地址并进行重定位。
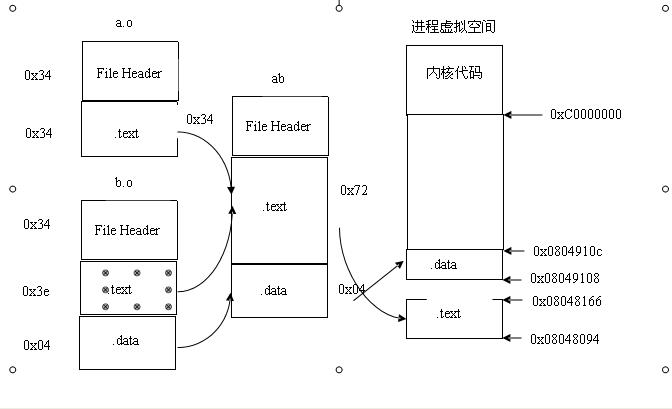
静态链接的整个过程分为两步:
第一步:空间和地址分配。扫描所有的输入目标文件,获得他们的各个段的长度、属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局符号表。这样,连接器将能够获得所有输入目标文件的段长度,并且将它们合并,计算出输出文件中各个段合并后的长度与位置,并建立映射关系。
这里可能会有一个问题:建立了什么样的映射关系。如上面的图1,你可能就会有所了解。映射关系就是指可执行文件与进程虚拟地址空间之间的映射。那么,这里程序还没有执行,更不会出现进程,哪里来的进程地址空间呢?此时虚拟存储器便发挥了很大的作用:虽然此时没有进程,但是每个进程的虚拟地址空间的格式都是一致的。所以,为可执行文件的每个段甚至每个符号符号分配地址也就不会有什么错了。注意:在链接之前,目标文件中的所有段的虚拟地址都是0,因为虚拟空间还没有被分配,默认都为0.等到链接之后,可执行文件中的各个段已经都被分配到了相应的虚拟地址。
第二步:符号解析与重定位
首先,符号解析。解析符号就是将每个符号引用与它输入的可重定位目标文件中的符号表中的一个确定的符号定义联系起来。
若找不到,则出现编译时错误。
其次是重定位。
动态链接
动态链接:将链接过程推迟到运行时再进行。它表示重定位发生在运行时而非编译后。
动态链接基本分为三步:先是启动动态链接器本身,然后装载所有需要的共享对象,最后重定位和初始化。
1,动态链接器自举
就我们所知道的,对普通的共享对象文件来说,它的重定位工作是由动态链接器来完成;它也可以依赖于其他共享对象,其中被依赖的共享对象由动态链接器负责链接和装载。那么,对于动态链接器本身呢,它也是一个共享对象,它的重定位工作由谁完成?它是否可以依赖于其他的共享对象文件?
动态链接器有其自身的特殊性:首先,动态链接器本身不可以依赖其他任何共享对象(人为控制);其次动态链接器本身所需要的全局和静态变量的重定位工作由它自身完成(自举代码)。
我们知道,在Linux下,动态链接器ld.so实际上也是一个共享对象,操作系统同样通过映射的方式将它加载到进程的地址空间中。操作系统在加载完动态链接器之后,就将控制权交给动态链接器。动态链接器入口地址即是自举代码的入口。动态链接器启动后,它的自举代码即开始执行。自举代码首先会找到它自己的GOT(全局偏移表,记录每个段的偏移位置)。而GOT的第一个入口保存的就是“.dynamic”段的偏移地址,由此找到动态链接器本身的“.dynamic”段。通过“.dynamic”段中的信息,自举代码便可以获得动态链接器本身的重定位表和符号表等,从而得到动态链接器本身的重定位入口,然后将它们重定位。完成自举后,就可以自由地调用各种函数和全局变量。
2,装载共享对象
完成自举后,动态链接器将可执行文件和链接器本身的符号表都合并到一个符号表当中,称之为“全局符号表”。然后链接器开始寻找可执行文件所依赖的共享对象:从“.dynamic”段中找到DT_NEEDED类型,它所指出的就是可执行文件所依赖的共享对象。由此,动态链接器可以列出可执行文件所依赖的所有共享对象,并将这些共享对象的名字放入到一个装载集合中。然后链接器开始从集合中取出一个所需要的共享对象的名字,找到相应的文件后打开该文件,读取相应的ELF文件头和“.dynamic”,然后将它相应的代码段和数据段映射到进程空间中。如果这个ELF共享对象还依赖于其他共享对象,那么将依赖的共享对象的名字放到装载集合中。如此循环,直到所有依赖的共享对象都被装载完成为止。
当一个新的共享对象被装载进来的时候,它的符号表会被合并到全局符号表中。所以当所有的共享对象都被装载进来的时候,全局符号表里面将包含动态链接器所需要的所有符号。
3,重定位和初始化
当上述两步完成以后,动态链接器开始重新遍历可执行文件和每个共享对象的重定位表,将表中每个需要重定位的位置进行修正,原理同前。
重定位完成以后,如果某个共享对象有“.init”段,那么动态链接器会执行“.init”段中的代码,用以实现共享对象特有的初始化过程。
此时,所有的共享对象都已经装载并链接完成了,动态链接器的任务也到此结束。同时装载链接部分也将告一段落!接下来便是程序的执行了。。。
对于动态链接和静态链接,各有千秋:如果多个程序都用到了一个库,那么每个程序都要将其链接到可执行文件中,非常冗余,动态链接的话,多个程序可以共享同一段代码,不需要在磁盘上存多份拷贝,节省内存,但是动态链接发生在启动或运行时,增加了启动时间,造成一些性能的影响。而且静态库不方便升级,必须重新编译,动态库的升级更加方便。这里不详细解释,感兴趣的读者可以阅读《程序员的自我修养》这本书。
以下两张图为.c文件的加工过程:

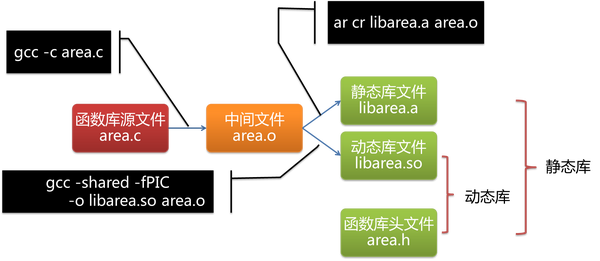
知乎上的轮子哥和其他大神解释得很清楚:
h:头文件,给编译器用来检查语法
lib:主要包含了如何找到函数的地址的信息,以及附带一些编译了一半的二进制数据
obj、o:编译了一半的二进制数据
dll、exe、out:可以运行(静态库就是lib文件,动态库就是dll文件),exe是win下的可执行文件,out是Linux下的可执行文件
代码签名
在iOS开发中,我们每次build之后,都会发现工程目录下多了一个.app文件
 在 .app目录中,有又一个叫_CodeSignature的子目录,这是一个plist文件,里面包含了程序的代码签名,你的程序一旦签名,就没有办法更改其中的任何东西,包括资源文件,可执行文件等,iOS系统会检查这个签名。
在 .app目录中,有又一个叫_CodeSignature的子目录,这是一个plist文件,里面包含了程序的代码签名,你的程序一旦签名,就没有办法更改其中的任何东西,包括资源文件,可执行文件等,iOS系统会检查这个签名。
签名过程本身是由命令行工具 codesign 来完成的。如果你在 Xcode中build一个应用,这个应用构建完成之后会自动调用codesign 命令进行签名,这也是Link之后的一个关键步骤。
更多详情请看我的另一篇博客iOS签名机制。
使用阶段——APP启动流程
在经过一系列处理后,终于形成一个可以在系统上跑起来的可执行程序,剩下的就是启动运行。即装载到内存中运行。
iOS触摸事件的流动见:iOS触摸事件的流动。
下图是App启动流程的关键节点展示:

关于该图的详细解读,请参考这篇文章:由App的启动说起
main函数之前——从系统开始说起
铺垫:iOS 系统架构
Mac系统是基于Unix内核的图形化操作系统,Mac OS 和 iOS 系统架构的对比分析发现,Mac OS和iOS的系统架构层次只有最上面一层不同,Mac是Cocoa框架,而iOS是Cocoa Touch框架,其余的架构层次都是一样的。

Core OS是用FreeBSD和Mach所改写的一个名叫Darwin的开放原始码操作系统, 是开源、符合POSIX标准的一个Unix核心。这一层包含并提供了整个iPhone OS的一些基础功能,比如:硬件驱动, 内存管理,程序管理,线程管理(POSIX),文件系统,网络(BSD Socket),以及标准输入输出等等,所有这些功能都会通过C语言的API来提供。

核心OS层的驱动提供了硬件和系统框架之间的接口。然而,由于安全的考虑,只有有限的系统框架类能访问内核和驱动。iPhone OS提供了许多访问操作系统低层功能的接口集,iPhone 应用通过LibSystem库来访问这些功能,这些接口集有线程(POSIX线程)、网络(BSD sockets)、文件系统访问、标准I/O、Bonjour和DNS服务、现场信息(Locale Information)、内存分配和数学计算等。
Core Services在Core OS基础上提供了更为丰富的功能, 它包含了Foundation.Framework和Core Foundation.Framework, 之所以叫Foundation,就是因为它提供了一系列处理字符串,排列,组合,日历,时间等等的基本功能。
Foundation是属于Objective-C的API,Core Fundation是属于C的API。另外Core servieces还提供了如Security(用来处理认证,密码管理,安全性管理等), Core Location, SQLite和Address Book等功能。
核心基础框架(CoreFoundation.framework)是基于C语言的接口集,提供iPhone应用的基本数据管理和服务功能。该框架支持Collection数据类型(Arrays、 Sets等)、Bundles、字符串管理、日期和时间管理、原始数据块管理、首选项管理、URL和Stream操作、线程和运行循环(Run Loops)、端口和Socket通信。
核心基础框架与基础框架是紧密相关的,它们为相同的基本功能提供了Objective-C接口。如果开发者混合使用Foundation Objects 和Core Foundation类型,就能充分利用存在两个框架中的”toll-free bridging”技术(桥接)。toll-free bridging使开发者能使用这两个框架中的任何一个的核心基础和基础类型。
从exec()开始
main()函数是整个程序的入口,在程序启动之前,系统会调用exec()函数。
在Unix中exec和system的不同在于,system是在单独的进程中执行命令,完了还会回到你的程序中。而exec函数是直接在你的进程中执行新的程序,新的程序会把你的程序覆盖,除非调用出错,否则你再也回不到exec后面的代码,也就是当前的程序变成了exec调用的那个程序了。
UNIX 提供了 6 种不同的 exec 函数供我们使用。
#include <unistd.h>
int execl(const char *pathname, const char *arg0, ... /* (char *)0 */);
int execv(const char *pathname, char *const argv[]);
int execle(const char *pathname, const char *arg0, ... /* (char *)0, char *const envp[] */);
int execve(const char *pathname, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, ... /* (char *)0 */);
int execvp(cosnt char *filename, char *const argv[]);
通过分析我们发现,含有 l 和 v 的 exec 函数的参数表传递方式是不同的。含有 e 结尾的 exec 函数会传递一个环境变量列表。含有 p 结尾的 exec 函数取的是新程序的文件名作为参数,而其他exec 函数取的是新程序的路径。如果函数出错则返回-1,若成功则没有返回值。其中只有execve是真正意义上的系统调用,其它都是在此基础上经过包装的库函数。
exec函数族的作用是根据指定的文件名找到可执行文件,并用它来取代调用进程的内容,换句话说,就是在调用进程内部执行一个可执行文件。这里的可执行文件既可以是二进制文件,也可以是任何Unix下可执行的脚本文件。
#####铺垫:动态链接库
iOS 中用到的所有系统 framework 都是动态链接的,类比成插头和插排,静态链接的代码在编译后的静态链接过程就将插头和插排一个个插好,运行时直接执行二进制文件;而动态链接需要在程序启动时去完成“插插销”的过程,所以在我们写的代码执行前,动态连接器需要完成准备工作。
iOS中的相关文件有如下几种:Dylib,动态链接库(又称 DSO 或 DLL);Bundle,不能被链接的 Dylib,只能在运行时使用 dlopen() 加载,可当做 macOS 的插件;Framework,包含 Dylib 以及资源文件和头文件的文件夹。
动态链接库是一组源代码的模块,每个模块包含一些可供应用程序或者其他动态链接库调用的函数,在应用程序调用一个动态链接库里面的函数的时候,操作系统会将动态链接库的文件映像映射到进程的地址空间中,这样进程中所有的线程就可以调用动态链接库中的函数了。动态链接库加载完成后,这个时候动态链接库对于进程中的线程来说只是一些被放在地址进程空间附加的代码和数据,操作系统为了节省内存空间,同一个动态链接库在内存中只有一个,操作系统也只会加载一次到内存中。
静态链接库与动态链接库都是共享代码的方式,如果采用静态链接库,则无论你愿不愿意,lib中的指令都全部被直接包含在最终生成的包文件中了。但是若使用动态链接库,该动态链接库不必被包含在最终包里,包文件执行时可以“动态”地引用和卸载这个与安装包独立的动态链接库文件。静态链接库和动态链接库的另外一个区别在于静态链接库中不能再包含其他的动态链接库或者静态库,而在动态链接库中还可以再包含其他的动态或静态链接库。
Linux中静态函数库的名字一般是libxxx.a;利用静态函数库编译成的文件比较大,因为整个函数库的所有数据都会被整合进目标代码中。编译后的执行程序不需要外部的函数库支持,因为所有使用的函数都已经被编译进去了。当然这也会成为他的缺点,因为如果静态函数库改变了,那么你的程序必须重新编译。
iOS开发中静态库和动态库是相对编译期和运行期的。静态库在程序编译时会被链接到目标代码中,程序运行时将不再需要载入静态库。而动态库在程序编译时并不会被链接到目标代码中,只是在程序运行时才被载入,因为在程序运行期间还需要动态库的存在。
iOS中静态库可以用.a或.Framework文件表示,动态库的形式有.dylib和.framework。系统的.framework是动态库,一般自己建立的.framework是静态库。
.a是一个纯二进制文件,.framework中除了有二进制文件之外还有资源文件。.a文件不能直接使用,至少要有.h文件配合。.framework文件可以直接使用,.a + .h + sourceFile = .framework。
除了多了的CoreGraphics(被 UIKit 依赖)外,有两个默认添加的 lib:libobjc 即 objc 和 runtime,libSystem 中包含了很多系统级别 lib,列几个熟知的:
- libdispatch ( GCD )
- libsystem_c ( C语言库 )
- libsystem_blocks ( Block )
- libcommonCrypto ( 加密库,比如常用的 md5 函数 )
这些 lib 都是dylib格式(如 windows 中的 dll ),系统使用动态链接有几点好处:
- 代码共用:很多程序都动态链接了这些 lib,但它们在内存和磁盘中中只有一份
- 易于维护:由于被依赖的 lib 是程序执行时才 link 的,所以这些 lib 很容易做更新,比如libSystem.dylib 是 libSystem.B.dylib 的替身,哪天想升级直接换成 libSystem.C.dylib 然后再替换替身就行了
- 减少可执行文件体积:相比静态链接,动态链接在编译时不需要打进去,所以可执行文件的体积要小很多
#####dyld—Apple的动态链接器
基于上面的分析,在exec()时,系统内核把应用映射到新的地址空间,每次起始位置都是随机的。然后使用dyld 加载 dylib 文件(动态链接库),dyld 在应用进程中运行的工作就是加载应用依赖的所有动态链接库,准备好运行所需的一切,它拥有和应用一样的权限。
dyld(the dynamic link editor),系统 kernel 做好启动程序的初始准备后,交给 dyld 负责,援引并翻译《 Mike Ash 这篇 blog 》对 dyld 作用顺序的概括:
- 从 kernel 留下的原始调用栈引导和启动自己
- 将程序依赖的动态链接库递归加载进内存,当然这里有缓存机制
- non-lazy 符号立即 link 到可执行文件,lazy 的存表里
- Runs static initializers for the executable
- 找到可执行文件的 main 函数,准备参数并调用
- 程序执行中负责绑定 lazy 符号、提供 runtime dynamic loading services、提供调试器接口
- 程序main函数 return 后执行 static terminator
- 某些场景下 main 函数结束后调 libSystem 的 _exit 函数
#####ImageLoader
这个image不是图片的意思,它大概表示一个二进制文件(可执行文件或so文件),里面是被编译过的符号、代码等,所以ImageLoader作用是将这些文件加载进内存,且每一个文件对应一个ImageLoader实例来负责加载。
两步走:
- 在程序运行时它先将动态链接的 image 递归加载
- 再从可执行文件 image 递归加载所有符号
所有这些都发生在我们真正的main函数执行前。
#####runtime 与 +load
刚才讲到 libSystem 是若干个系统 lib 的集合,所以它只是一个容器 lib 而已,而且它也是开源的,里面实质上就一个文件,init.c,由 libSystem_initializer 逐步调用到了 _objc_init,这里就是 objc 和 runtime 的初始化入口。
除了 runtime 环境的初始化外,_objc_init中绑定了新 image 被加载后的 callback:
dyld_register_image_state_change_handler(
dyld_image_state_bound, 1, &map_images);
dyld_register_image_state_change_handler(
dyld_image_state_dependents_initialized, 0, &load_images); 可见 dyld 担当了 runtime 和 ImageLoader 中间的协调者,**当新 image 加载进来后交由 runtime 大厨去解析这个二进制文件的符号表和代码**。
用断点法,断住神秘的 +load 函数:

清楚的看到整个调用栈和顺序:
- dyld 开始将程序二进制文件初始化
- 交由 ImageLoader 读取 image,其中包含了我们的类、方法等各种符号
- 由于 runtime 向 dyld 绑定了回调,当 image 加载到内存后,dyld 会通知 runtime 进行处理
- runtime 接手后调用 map_images 做解析和处理,接下来 load_images 中调用 call_load_methods 方法,遍历所有加载进来的 Class,按继承层级依次调用 Class 的 +load 方法和其 Category 的 +load 方法
至此,可执行文件中和动态库所有的符号(Class,Protocol,Selector,IMP,…)都已经按格式成功加载到内存中,被 runtime 所管理,再这之后,runtime 的那些方法(动态添加 Class、swizzle 等等才能生效)
#####总结 整个事件由动态链接器(dyld)主导,完成运行环境的初始化后,配合 ImageLoader 将二进制文件按格式加载到内存,动态链接依赖库,并由 runtime 负责加载成 objc 定义的结构,所有初始化工作结束后,dyld 调用真正的 main 函数。
值得说明的是,这个过程远比写出来的要复杂,这里只提到了 runtime 这个分支,还有像 GCD、XPC 等重头的系统库初始化分支没有提及(当然,有缓存机制在,它们也不会玩命初始化),总结起来就是 main 函数执行之前,系统做了茫茫多的加载和初始化工作,但都被很好的隐藏了,我们无需关心。
在这个main函数里
#import <UIKit/UIKit.h>
#import "AppDelegate.h"
int main(int argc, char * argv[])
{
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
函数原型为
UIKIT_EXTERN int UIApplicationMain(int argc, char *argv[], NSString *principalClassName, NSString *delegateClassName);
首先说说UIKIT_EXTERN,
#ifdef __cplusplus
#define UIKIT_EXTERN extern "C" __attribute__((visibility("default")))
#else
#define UIKIT_EXTERN extern __attribute__((visibility ("default")))
#endif
区分在是否定义了__cplusplus(C++),__cplusplus标示符用来判断程序是用c还是c++编译程序编译的。当编译c++程序时,这个标示符会被定义,编译c程序时,不会定义。接着对全句理解,如果已经宏定义了__cplusplus,则当前源代码被当作C++源代码处理。否则当前源代码被当做C源代码处理),即extern "C" __attribute__((visibility ("default")))。
extern "C"很好理解,在c++发明之初,为了兼容在当时正处主流的C语言,按照C编译方式进行编译的作用。可以理解为extern "C"就是告诉编译器(也就是Xcode)在编译的时候,要按照原来C语言的编译方式对(全局)函数和变量进行编译。
C++是一种“不完全的面相对象语言”,对比C/C++ 两种编译方式,C++支持重载,从而使得函数的编译方式不得不同于C的编译。举个栗子,有个函数,更新学生信息的void upDataStudentInfo(int, int)。C方式去编译此函数,不会对函数名进行特殊处理,编译后的函数名为_upDataStudentInfo,反观C++方式的编译,为了支持重载,upDataStudentInfo函数会变成类似_upDataStudentInfo_int_int的函数名,同样void upDataStudentInfo(float, int)会编译成_upDataStudentInfo_float_int类似的函数名。这些都可在.obj文件中查看。此处对于C/C++混编互调的深层学习以及使用,不做分析,我只是个搞iOS的,在编译后寻找函数名等多少也能说出些来,但实在不算熟悉,就不误人子弟了。
接下来就是__attribute__((visibility ("default"))),同出于C系语言,__attribute__是用来设置属性的,包括函数、变量、类型,这里我们使用的是设置函数的属性,__attribute__听传闻说是自测利器,同样在C中,或者C++中,作为入门级的iOSer,理解就可。visibility属性是设置将本项目的函数作为库使用时的可见性。设置了__attribute__((visibility ("default"))),函数的public属性对外可见。
总结成一句话,UIKIT_EXTERN就是将函数修饰为兼容以往C编译方式的、具有extern属性(文件外可见性)、public修饰的方法或变量库外仍可见的属性。
继续分析int UIApplicationMain(int argc, char *argv[], NSString * __nullable principalClassName, NSString * __nullable delegateClassName);
前面两个参数出于main,从第三个开始NSString * __nullable principalClassName,一个字符串类型的参数principalClassName,直译为主要类,必须为UIApplication或者其子类,代表着当前app自身。并且如果此参数为nil的话,则默认为@"UIApplication"。
第四个参数delegateClassName,代理类。在UIApplication中有个delegate的变量,delegate遵守UIApplicationDelegate协议负责程序的生命周期。UIApplication 接收到所有的系统事件和生命周期事件时,都会把事件传递给UIApplicationDelegate进行处理,至于为什么没让UIApplication自己去实现,涉及到了上帝类、框架类,过深,不讲。
综合来说UIApplicationMain主要负责三件事
1、从给定的类名初始化应用程序对象,也就是初始化UIApplication或者子类对象的一个实例,如果你在这里给定的是nil,那么 系统会默认UIApplication类,也就主要是这个类来控制以及协调应用程序的运行。在后续的工作中,你可以用静态方法sharedApplication 来获取应用程序的句柄。
2、从给定的应用程序委托类,初始化一个应用程序委托。并把该委托设置为应用程序的委托,这里就有如果传入参数为nil,会调用函数访问 Info.plist文件来寻找主nib文件,获取应用程序委托。
3、启动主事件循环(runloop),并开始接收事件。
main函数之后
关于iOS卡顿优化请参考本人另一篇博文iOS卡顿及优化和这一篇文章iOS 事件处理机制与图像渲染过程。
下图为iOS App启动流程图:

-
main函数
-
UIApplicationMain
- 创建UIApplication对象
- 创建UIApplication的delegate对象
- delegate对象开始处理(监听)系统事件(没有storyboard)
- 程序启动完毕的时候, 就会调用代理的application:didFinishLaunchingWithOptions:方法
- 在application:didFinishLaunchingWithOptions:中创建UIWindow
- 创建和设置UIWindow的rootViewController
- 显示窗口
- 根据Info.plist获得最主要storyboard的文件名,加载最主要的storyboard(有storyboard)
- 创建UIWindow
- 创建和设置UIWindow的rootController
- 显示窗口
AppDelegate的代理方法:
//app启动完毕后就会调用
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions{
}
//app程序失去焦点就会调用
- (void)applicationWillResignActive:(UIApplication *)application{
}
//app进入后台的时候调用, 一般在这里保存应用的数据(游戏数据,比如暂停游戏)
- (void)applicationDidEnterBackground:(UIApplication *)application{
}
//app程序程序从后台回到前台就会调用
- (void)applicationWillEnterForeground:(UIApplication *)application{
}
//app程序获取焦点就会调用
- (void)applicationDidBecomeActive:(UIApplication *)application{
}
// 内存警告,可能要终止程序,清除不需要再使用的内存
- (void)applicationDidReceiveMemoryWarning:(UIApplication *)application{
}
// 程序即将退出调用
- (void)applicationWillTerminate:(UIApplication *)application{
}
ViewController的生命周期

当你alloc并init了一个ViewController时,这个ViewController应该是还没有创建view的。ViewController的view是使用懒加载方式创建,就是说你调用的view属性的getter:[self.view]。在getter里会先判断view是否创建,如果没有创建,那么会调用loadView来创建view。loadView完成时会继续调用viewDidLoad。
loadView和viewDidLoad的一个区别就是:loadView时还没有view。而viewDidLoad时view已经创建好了。 当view被添加其他view中之前时,会调用viewWillAppear,而之后会调用viewDidAppear。 当view从其他view中移出之前时,会调用viewWillDisAppear,而之后会调用viewDidDisappear。 当view不在使用,而且是disappeared,受到内存警告时,那么viewController会将view释放并将其指向nil。
设计良好的VC
1、init里不要出现创建view的代码。良好的设计,在init里应该只有相关数据的初始化,而且这些数据都是比较关键的数据。init里不要调self.view,否则会导致viewcontroller创建view。(因为view是lazyinit的)。
2、loadView:只初始化view,一般用于创建比较关键的view如tableViewController的tabView,UINavigationController的navgationBar,不可调用view的getter(在掉super loadView前),最好也不要初始化一些非关键的view。如果你是从nib文件中创建的viewController在这里一定要首先调用super的loadView方法,但建议不要重载这个方法。
3、viewDidLoad:这时候view已经有了,最适合创建一些附加的view和控件了。有一点需要注意的是,viewDidLoad会调用多次(viewcontroller可能多次载入view,参见图2)。
4、viewWillAppear:这个一般在view被添加到superview之前,切换动画之前调用。在这里可以进行一些显示前的处理。比如键盘弹出,一些特殊的过程动画(比如状态条和navigationbar颜色)。
5、viewDidAppear:一般用于显示后,在切换动画后,如果有需要的操作,可以在这里加入相关代码。
6、viewDidUnload:这时候viewController的view已经是nil了。由于这一般发生在内存警告时,所以在这里你应该将那些不在显示的view释放了。比如你在viewcontroller的view上加了一个label,而且这个label是viewcontroller的属性,那么你要把这个属性设置成nil,以免占用不必要的内存,而这个label在viewDidLoad时会重新创建。
View加载顺序
1. loadView
2. viewDidLoad
3. viewWillAppear
4. viewWillLayoutSubviews
5. viewDidLayoutSubviews
6. viewDidAppear
7. viewWillDisappear
8. viewDidDisappear
一些方法的使用时机
+ (void)load; //应用程序启动就会调用的方法,在这个方法里写的代码最先调用。
+ (void)initialize; //用到本类时才调用,这个方法里一般设置导航控制器的主题等,如果在后面的方法设置导航栏主题就太迟了!
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary*)launchOptions; //这个方法里面会创建UIWindow,设置根控制器并展现,比如某些应用程序要加载授权页面也是在这加,也可以设置观察者,监听到通知切换根控制器等。
- (void)awakeFromNib; //在使用IB的时候才会涉及到此方法的使用,当.nib文件被加载的时候,会发送一个awakeFromNib的消息到.nib文件中的每个对象,每个对象都可以定义自己的awakeFromNib函数来响应这个消息,执行一些必要的操作。在这个方法里设置view的背景等一系列普通操作。
- (void)loadView; //创建视图的层次结构,在没有创建控制器的view的情况下不能直接写 self.view 因为self.view的底层是:
if(_view == nil){
_view = [self loadView]
}
//这么写会直接造成死循环,如果重写这个loadView方法里面什么都不写,会显示黑屏。
- (void)viewWillLayoutSubviews; //视图将要布局子视图,苹果建议的设置界面布局属性的方法,这个方法和viewWillAppear里,系统的底层都是没有写任何代码的,也就是说这里面不写super 也是可以的。
- (void)layoutSubviews; //在这个方法里一般设置子控件的frame。
- (void)drawRect:(CGRect)rect; //UI控件都是画上去的,在这一步就是把所有的东西画上去。drawRect方法只能在加载时调用一次,如果后面还需要调用,比如下载进度的圆弧,需要一直刷帧,就要使用setNeedsDisplay来定时多次调用本方法。
- (void)applicationDidBecomeActive:(UIApplication *)application; //这是AppDelegate的应用程序获取焦点方法,真正到了这里,才是所有东西全部加载完毕。
启动分析
应用启动时,会播放一个启动动画。iPhone上是400ms,iPad上是500ms。如果应用启动过慢,用户就会放弃使用,甚至永远都不再回来。为了防止一个应用占用过多的系统资源,开发iOS的苹果工程师门设计了一个“看门狗”的机制。在不同的场景下,“看门狗”会监测应用的性能。如果超出了该场景所规定的运行间,“看门狗”就会强制终结这个应用的进程。
iOS App启动时会链接并加载Framework和static lib,执行UIKit初始化,然后进入应用程序回调,执行Core Animation transaction等。每个Framework都会增加启动时间和占用的内存,不要链接不必要的Framework,必要的Framework不要标记为Optional。避免创建全局的C++对象。
初始化UIKit时字体、状态栏、user defaults、Main.storyboard会被初始化。User defaults本质上是一个plist文件,保存的数据是同时被反序列化的,不要在user defaults里面保存图片等大数据。
对于 OC 来说应尽量减少 Class,selector 和 category 这些元数据的数量。编码原则和设计模式之类的理论会鼓励大家多写精致短小的类和方法,并将每部分方法独立出一个类别,但这会增加启动时间。在调用的地方使用初始化器,不要使用\atribute((constructor)) 将方法显式标记为初始化器,而是让初始化方法调用时才执行。比如使用 dispatch_once(),pthread_once() 或 std::once()。也就是在第一次使用时才初始化,推迟了一部分工作耗时。
建立网络连接前需要做域名解析,如果网关出现问题,dns解析不正常时,dns的超时时间是应用控制不了的。在程序设计时要考虑这些问题,如果程序启动时有网络连接,应尽快的结束启动过程,网络访问通过线程解决,而不阻塞主线程的运行。
写在文后—苹果编译器的前世今生
OS X 现在使用的编译器是 LLVM (Low Level Virtual Machine),在最初使用的是 GCC作为官方的编译器,但是由于下面的众多限制,apple 使用了自己的一套编译器。
Clang 比 GCC 好在哪里? ——知乎
GCC 原名为GNU C语言编译器,它原本只能处理 C语言,后来扩展了Objective-C、Java等语言,但是对于Objective-C的处理还是存在众多不便:GCC 效率低下、性能不强等。苹果开发自己的编译器,有利于开展自己的工具链,比如后期做 Swift、lldb 等。借用 sunnyxx的图片 来展现下 llvm 的基本架构

编译器分别编译器前端(clang)和编译器后端,编译器前端负责产生机器无关的中间代码,编译器后端负责对中间代码进行优化并转化为目标机器代码,对于为什么需要中间代码这个东西,看个图就一目了然啦(IR:intermediate representation中间表示)
Clang的任务:预处理、词法分析、语法分析、语义分析、静态分析、生成中间代码。
- 预处理:以#开头的代码预处理。包括引入的头文件和自定义宏。
- 词法分析:每一个.m源文件的声明和定义从string转化为特殊的标记流。
- 语法分析:将标记流解析成一颗抽象语法树( abstract syntax tree-AST)。
- 静态分析:包含类型检查和其他检查。
- 中间代码生成:生成LLVM代码。
LLVM的任务:将代码进行优化并产生汇编代码。
- 汇编器:将可读的汇编代码转换为机器代码,最终创建一个目标对象.o文件。
链接器的任务:把目标文件和库相连,最终输出可运行文件:a.out。